
我是个懒人,能采集的绝对不会复制的!!!
下面说一下我在自动采集大致思路遇到的问题跟解决方法,各位大佬可以别嘲笑我啊!
采集最新数据——>匹配当天日期获取文章id——>把id拼接成url在进行curl采集——>把采集到的数据替换过滤一下——>采集入库并邮件提醒——>加入宝塔计划任务每天执行一次
上面就是我的大概思路,看起来就几个步骤关键我是小菜鸟,这几个步骤手戳了一天!
第一步采集最新数据
我选择的目标网站有一个特点,首页或者有一个页面聚合了发布的最新文章!
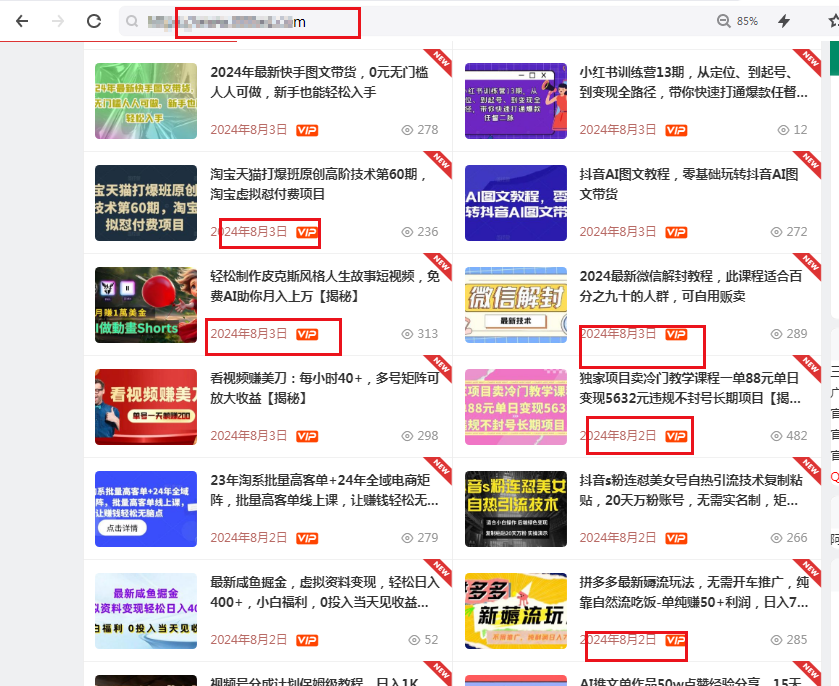 然后直接curl,截取关键地方就行
然后直接curl,截取关键地方就行
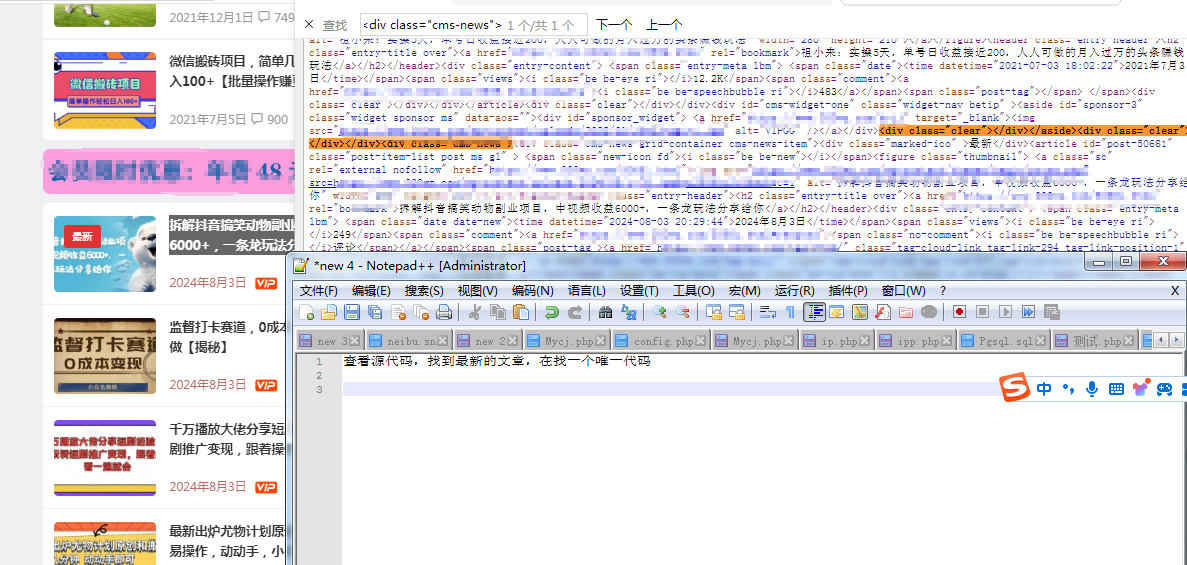 接下来我们要做的就是处理数据,匹配到两个关键的地方,文章的id和文章更新的日期,把采集到的数据做成一个数组,然后匹配当天日期获取文章id,最后循环输出当天所有的信息。
接下来我们要做的就是处理数据,匹配到两个关键的地方,文章的id和文章更新的日期,把采集到的数据做成一个数组,然后匹配当天日期获取文章id,最后循环输出当天所有的信息。
上代码
$data = [
['date' => '2023-04-01', 'info' => '123'],
['date' => '2024-08-02', 'info' => '456'],
['date' => '2023-04-03', 'info' => '789'],
];
$today = '2024-08-03';
//$today = date('Y-m-d');
$todayData = array_filter($data, function($item) use ($today) {
return $item['date'] === $today;
});
$infoValues = array();
foreach ($todayData as $item) {
if (isset($item['info'])) {
$infoValues[] = $item['info'];
}
}
if(empty(count($infoValues))){
echo '当天无更新';
}else {
for ($i=1; $i<=count($infoValues); $i++){
echo "xxxx.php?so=".$infoValues[$i-1]."";
//解析匹配到的文章id
//格式xxxx.php?so=123 xxxx.php?so=456 xxxx.php?so=789
}
}
我把这个保存命名为1.php
当时到这一步的时候不会搞了,要把链接的内容采集处理,还要解析下载地址,还要入库!
代码量有点大了,一些变量跟方法的命名容易冲突(我写代码就固定的几个名字~~~~)
想了一会,我重新做了一个页面再次curl,目标地址就是这个xxx.com/1.php
重新处理模拟登陆过滤标签采集入库之类的。
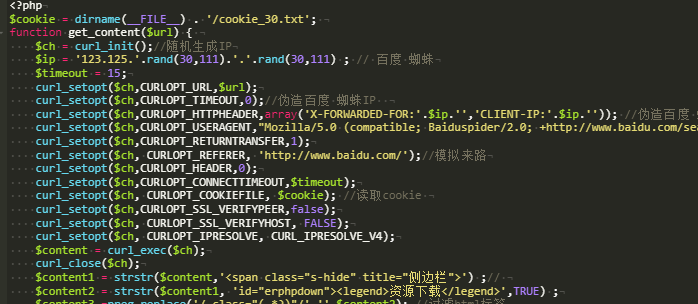
 大家看看思路就行,代码就不全发出来了,免得大佬笑话我
大家看看思路就行,代码就不全发出来了,免得大佬笑话我
这里有个重点,就是typecho的超链接太不人性了
[点击下载][10]
[10]: https://pan.baidu.com
[图片描述][10]
[10]: https://tutututu.png
这一个是超链接一个是图片,可以看出来两个都是命名的是10
如果这两个出现在同一个页面里还没有改编号,大家可以猜一下会变成什么样?
对,入库后会变成
[点击下载][10]
[10]: https://tutututu.png
就是编号重复造成的
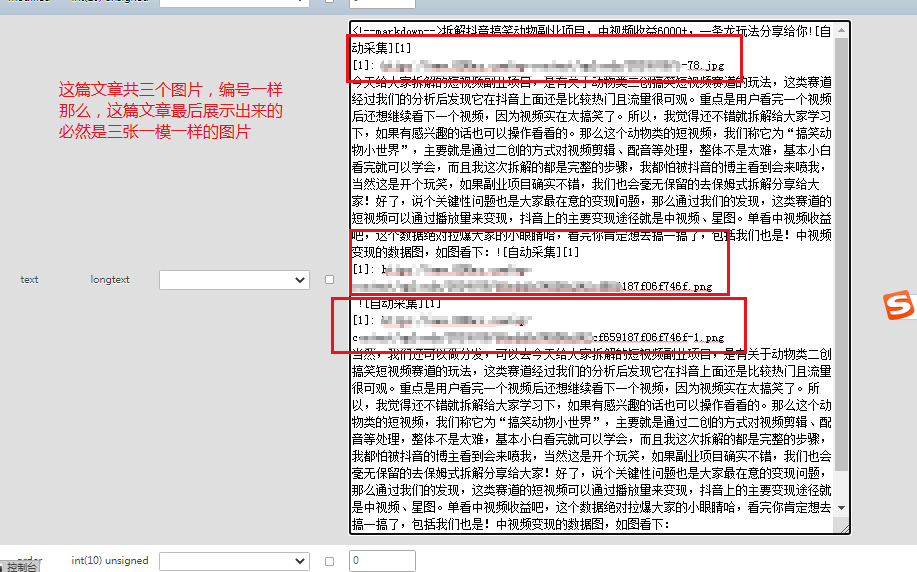

所以如果采集的时候遇到好几张图片的情况下一定要注意这个编号。(我是直接入库的,在网站自带的模版测试下的结果,其他模版不清楚)
还有这里
 入库的时候最起码是这四个,标题,正文,更新时间,最后这个不知道是干啥的给它赋值1就OK,少了它还真不行。正文必须要以<!--markdown-->开始,组合字符串的时候直接写进去就行!
入库的时候最起码是这四个,标题,正文,更新时间,最后这个不知道是干啥的给它赋值1就OK,少了它还真不行。正文必须要以<!--markdown-->开始,组合字符串的时候直接写进去就行!
还有这个分类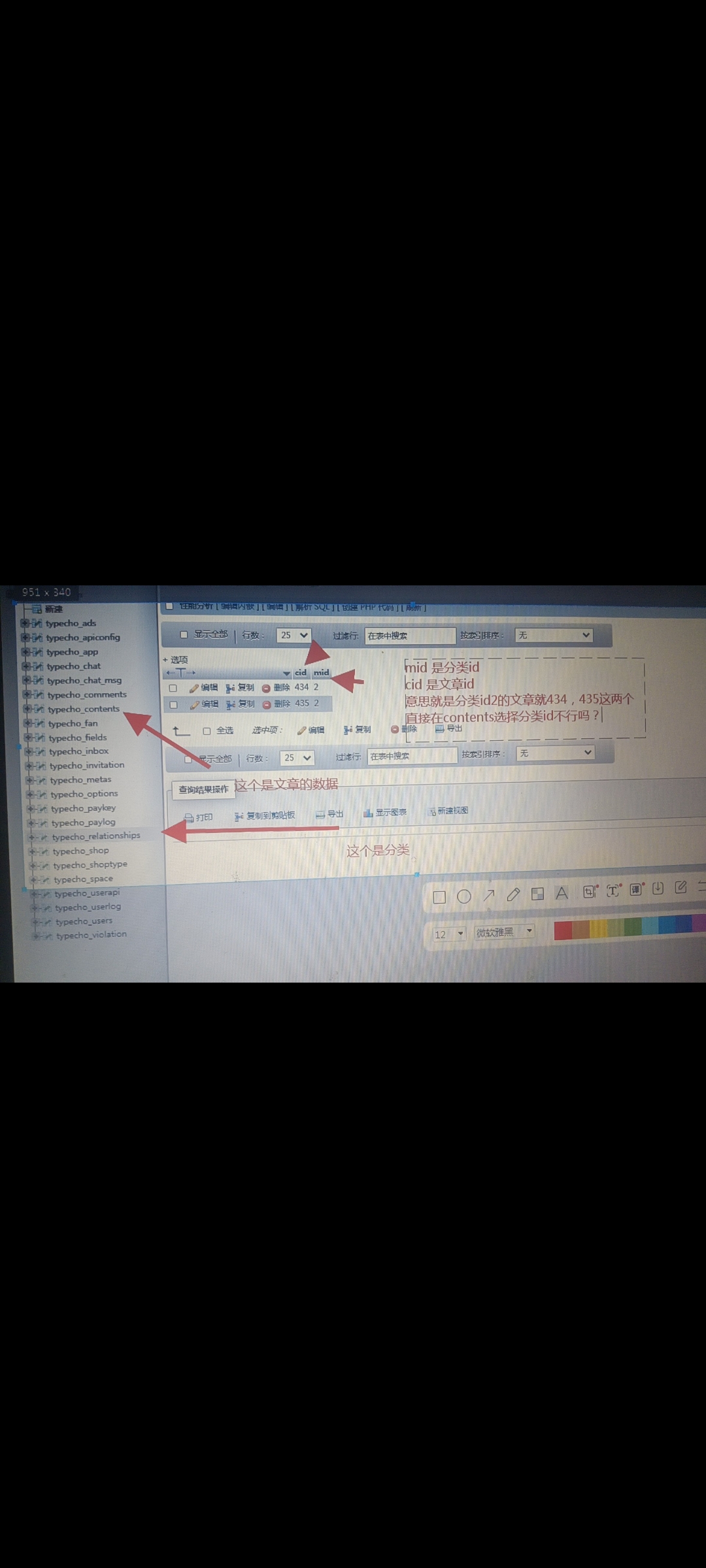
好像还有一些要注意的地方就是想不起来了,想起来的时候再说吧!
大家有啥不明白的地方可以在评论区留言!或者哪个步骤有好的想法可以提个建议感激不尽!


 。
。